DeepSeek moment 确实是把整个行业都震撼到了,几百 B 的大稀疏 MoE 架构,多头潜在注意力(MLA)把成本打下来,模型能力也有了质的飞跃。
V3 发布(2024 年底)后的半年多里,模型架构没有太大的变动。
一年半后的今天,业务场景已经从简单的 Chat,发展到了 Agentic,上下文从百 K 发展到了 1M,模型架构也有了新一轮的明显跃迁。
本文主要从推理的视角,谈谈个人的看法。
一、模型大小:参数量与激活量双增长
671B/37B(V3)→ 1.6T/49B(V4-Pro)→ 2.8T/104B(K3)
估计后续的主流 SOTA 模型,都得是 T 级参数量,100B 级激活量了。
参数、激活量的上涨,加剧了显存容量和带宽的压力,存储股票最近涨得一塌糊涂也是有原因的。
二、FFN/MoE:继续稀疏化,叠加压缩
256 选 8(V3)→ 384 选 6(V4-Pro)→ 896 选 16(K3),专家数量变多,专家激活比例变少。
有趣的是,Kimi K3 把 MLA 的低秩压缩思路也用到了 MoE 上(LatentMoE),可以节约显存、通信带宽。
三、注意力:四条路线,混合发展
压缩。 MLA 之后,V4 更进了一步:CSA(KV 沿序列维 4:1 压缩后再稀疏选择)与 HCA(128:1 激进压缩 + 稠密)按 1:1 交错堆叠,压缩程度更深。
稀疏化。 V3.2 首提 DSA:Lightning Indexer + top-2048 选择;GLM-5.2 再加 IndexShare——每 4 层共享索引,78 层仅 21 层保留独立索引。
线性。 Kimi KDA 与 Qwen Gated DeltaNet 同为 3:1 混合:75% 线性层 + 25% 全注意力锚层,KV cache 减少 75%。
滑动窗口。 V4-Flash 前 2 层是纯 SWA 层;V4 的 CSA 与 HCA 层也都保留最近 128 token 的完整 KV 滑窗分支;Step 3.5 Flash 则是 SWA:Full=3:1 的混合。
四条路线也不是分开演进的,DeepSeek V4 系列是玩得最花的,混合注意力还是很有希望的。
四、投机采样成了标配
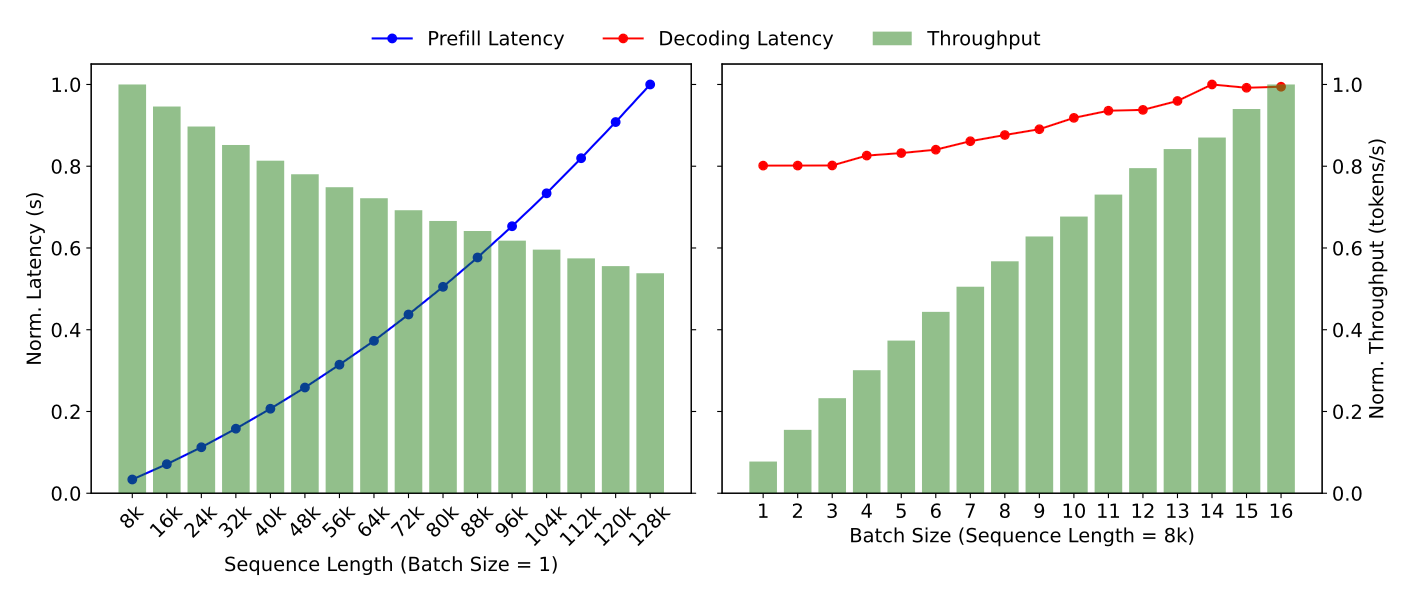
解码是 memory-bound:即使只产 1 个 token,也要读一遍权重,带宽利用率太低。
投机采样的思路就是,拿算力换显存带宽:用一个便宜的 draft(比如一个小的 MTP 头)一次猜出多个 token,大模型一次前向并行验证,猜中的直接收下。验证是并行的,多花的算力本来利用率也不高,换来的却是实打实的解码提速。
有意思的是,DeepSeek 还专门发布了 DSpark 投机采样框架,根据算力需求和接受概率来动态决定投机长度,避免傻大粗式的算力浪费。
参数量、激活量越来越大,显存带宽又很有限,Agentic 场景下对时延的要求也更高了。用本来利用不满的算力换解码速率,也是众望所归了。
五、残差流改进
层数从 61(V3)堆到 93(K3),模型越堆越深,逐层均匀累加的残差流开始出问题:每层的贡献被不断稀释,信息混合方式太单一,也被动刀了
K3 的 AttnRes 把残差换成跨层选择性检索,V4 的 mHC 则把残差流扩成 4 通道,用双随机矩阵流形约束保深层稳定。
虽然带来一些额外开销,但对整体推理成本影响不大,收益主要在模型能力。
小结
回看这一年半的模型架构演进,几条线索其实都指向同一个方向:推理成本。
参数量上去了,靠更稀疏的 MoE 压住激活量;上下文长了,靠压缩、稀疏、线性、滑窗把 KV cache 打下来;解码慢了,靠投机采样拿闲置算力换带宽。
当然,残差流这条线,钱花在了深度能力上,不在成本上。
模型架构的竞赛,已经从单纯的”更聪明”,变成了”更聪明的同时,把每个 token 的成本和时延做得更低”。
国内的开源模型厂商,在算力受限的情况下,把成本打下来的同时,模型能力还能继续追赶国际 SOTA,很有希望。
最后,虽然模型架构有了很多演进,不过大基调还是没有变动,依旧是 Transformer 架构,Attention is All You Need 还是真理。
大模型的本质是信息的压缩,推理过程本质是,海量参数读取、矩阵乘的暴力计算,这个范式依旧没变。
下一篇再来分析下,从通算在线服务,到大模型推理服务,这两种范式的跃迁,对于计算机基础设施的影响。
附:主流模型架构对比
| 维度 | Kimi K3 | DeepSeek V4-Pro | DeepSeek V4-Flash | GLM-5.2 | DeepSeek V3(基线) |
|---|---|---|---|---|---|
| 发布时间 | 2026-07-16 | 2026-04-24(预览) | 2026-04-24(预览) | 2026-06 | 2024-12-26 |
| 总参数 | 2.8T | 1.6T | 284B | 744B(HF 口径 753B) | 671B |
| 激活参数 | 104B | 49B | 13B | 40B | 37B |
| 激活率 | 3.7% | 3.0% | 4.6% | 5.4% | 5.5% |
| 层数 | 93(69 KDA + 24 Gated MLA) | 61(前 2 层 HCA + 30 CSA + 29 HCA) | 43(前 2 层纯 SWA + 21 CSA + 20 HCA) | 78(3 dense + 75 MoE) | 61(前 3 层 dense MLP) |
| 注意力方案 | KDA 线性注意力为主(3:1 混合) | CSA / HCA 1:1 交错;CSA 选 top-1024,128 头 × 512 维 | CSA / HCA 1:1 交错(CSA 首尾多 1 层);CSA 选 top-512,64 头 × 512 维 | MLA + DSA,IndexShare 每 4 层共享索引 | MLA(128 头,dense 全注意力,无稀疏/压缩分层) |
| MoE 配置 | 896 专家选 16 + 2 共享(LatentMoE) | 384 专家选 6 + 1 共享 | 256 专家选 6 + 1 共享 | 256 专家选 8 + 1 共享 | 256 专家选 8 + 1 共享(Sigmoid 打分) |
| 路由均衡 | Quantile Balancing(无均衡超参) | 辅助损失免费 + 前 3 层 Hash routing | 辅助损失免费 + 前 3 层 Hash routing | — | 辅助损失免费(该策略的开创者) |
| 跨层信息流 | AttnRes(跨层选择性检索) | mHC(4 通道流形残差) | mHC(4 通道) | 常规残差 | 常规残差 |
| 词表 | 163,840 | 128K | 128K | 154,880 | 129,280 |
| 模态 | 文本 + 视觉(MoonViT-V2,401M) | 纯文本 | 纯文本 | 纯文本 | 纯文本 |
| 权重精度 | MXFP4 + MXFP8(QAT) | FP4 专家 + FP8 | FP4 专家 + FP8 | BF16/FP8 官方发货(NVFP4 为 NVIDIA 衍生量化) | FP8 混合精度(训练开创者,BF16 权重发布) |
| 上下文 / 最大输出 | 1M / 131K | 1M / 384K | 1M / 384K | 1M / 131K | 128K |
| 智能指数(AA v4.1) | 57(开源第一,综合 Top3) | 44 | —(未单独上榜;简单 Agent 任务接近 Pro) | 51 | ≈14(已不在同一竞争层级) |
| API:输入(缓存未命中) | $3.00(¥20) | $0.435(¥3) | $0.14(¥1,最便宜) | $1.40(¥8) | 已退役(历史价 $0.27 / ¥2) |
| API:输入(缓存命中) | $0.30(¥2) | $0.003625(¥0.025) | $0.0028(¥0.02) | $0.26(¥2) | 已退役(历史价 $0.07) |
| API:输出 | $15.00(¥100,最贵) | $0.87(¥6) | $0.28(¥2,最便宜) | $4.40(¥28) | 已退役(历史价 $1.10 / ¥8) |