又是一年结束了,照例来总结总结~
输出是为了更多的思考
算上这篇,2023 一共写了 26 篇文章,很好的完成了计划:大致一个月两篇,有想法就多写写,不想写就歇着,这点我还是挺满意的
因为要输出,平常就会多思考,往深度了想,并且,文章算是一种相对系统性的表达,写作的过程也会让思考更加系统。有时候,写的过程中,还能发现一些理解错误
通常写一篇文章,也得花上个好几个小时,这种思考的深度还是有一些的
哈哈,当然也不是啥精雕细琢的,多是当前所做所想的一些总结而已
我给自己的定位是,主要是从自我总结的角度,来把事情讲清楚,要正确到位,并没有一定要让尽量多的人读懂
哈哈,当然也会尽量写得更清晰一些,只是主题内容本身多是一些技术细节,本来受众也不会多的
目前还没有打算写一些相对普世的科普文章(今年的 MoE 系列可能也算),或许明年会有一些尝试,比如,Envoy 的科普介绍
哈哈,本来今年有这个想法的,只能说太卷了,忙不过来了,哈哈~
效果
哈哈,好在各位看官捧场,今年写的文章还是有一些阅读量,尤其是几篇关于 cgo 的文章,估计是被平台推荐了
年中还舔着脸开过一阵打赏,收到了一批土豪老板的馈赠,搞得我都不太好意思了
后来开了文末广告,也能有一丢丢收入,几杯奶茶钱,主打一个体验生活了,哈哈
最让我看重的是,能吸引有一些朋友来交流,做技术还是蛮孤独的,碰上个同道中人,要懂得珍惜,哈哈~
QCon 广州
今年上半年还参与了一次 QCon 分享,终于是线下的了,能见到真人了,还是有点激动,厚着脸皮蹭了几个饭局,哈哈
QCon 这种输出要求会更高一些,准备自然也会更充分一些
对我来说,一方面是要更加体系化,另外更重要的是,让听众也能有所收获,也不能太随着自己性子来了
哈哈,我自己总体感觉也就还凑合,主办方还给发了个明星讲师,我也是受宠若惊 …
上下半场
哈哈,不吹水了,总结下今年的工作先
以半年为界,今年的上下两个半场,是肉眼可见的的状态不一样了
上半场 - 继续打野
上半年整体是去年的延续,玩玩新东西,搞搞开源,不亦乐乎
虽然年初也有定下今年要内部落地目标,但是呢,现实是推进并不太顺利
大家的精力比较分散,背着更重要的事情要忙,我呢,能推多少算多少,主要产出还是打野~
经过去年的体验把玩,今年打野感觉也更顺畅了一些,目的性更强了,推进力也更强了~
今年开源算是整个几个大活,不过,基本都发生在上半年~
从 github 的统计数据看,上半年的密集程度明显更高~

Envoy Go
数了一下,2023 一共给 Envoy 提了近 50 个 PR,主要集中在上半年,基本把 Envoy Go 给怼到了成熟稳定的状态。
也有幸吸引了一些社区玩家,甚至他们还能帮忙发现一些 bug,让我深感幸运的同时,也觉得有些愧疚。好在都能给快速修复,也给足大家信心
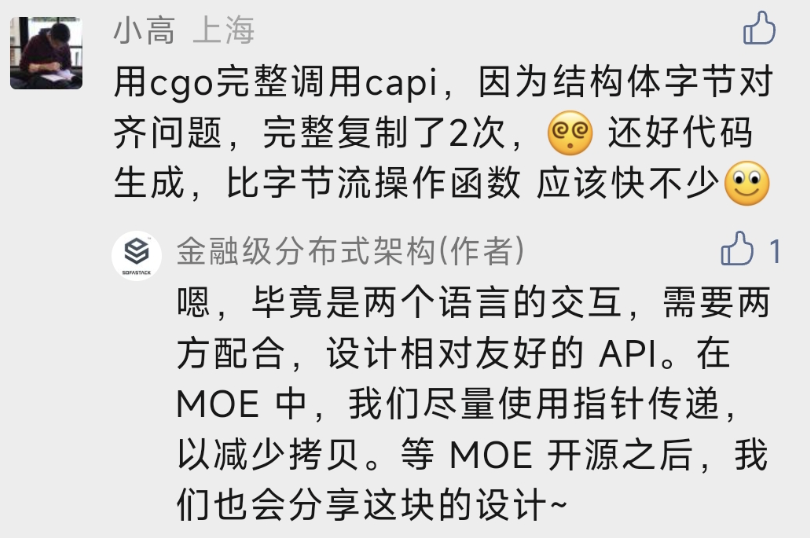
除了更成熟稳定,也解决了原来依赖 cgocheck=0,这个使用上的容易踩的坑。这个说实话,多少有点设计上的失误,主要还是对 cgo 了解的不够深入的情况下,对性能的过于执着 …
持续的迭代改进,Envoy 官方也对 Golang 扩展有了更多的认可
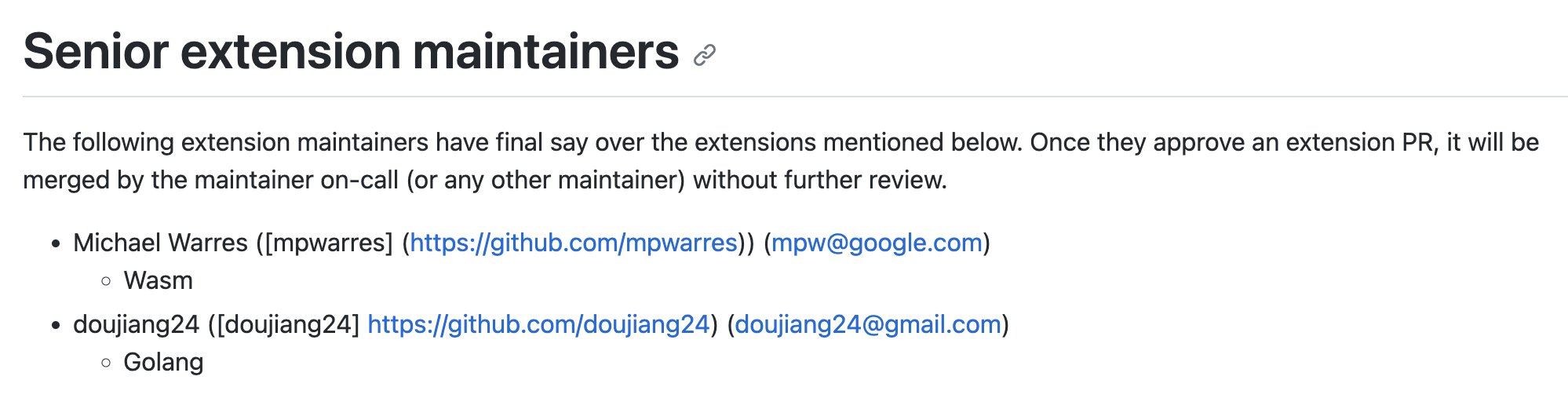
下半年我们先是申请了 extension maintainer,官方也是爽快的答应了
不过,发现 extension maintainer 用处比较有限,再申请 maintainer 的时候,Matt 大佬说,还要再多玩一玩其他的模块先,哈哈~
CGO
今年对 cgo 的研究更深入了一些,两个 cgo 优化怼进了 golang 主干
其中 CPU 的优化,去年已经怼了大半年了,今年也是想一鼓作气怼到底的
不过,我感觉,官网对 cgo 并不是很重视的,期间有一段时间感觉很简单。好在后面 iant 和 Cherry Mui 两位大佬都很给力,respect~
明年希望有空搞一搞 extra P 的优化,这个算是 cgo 头上的一朵乌云。
下半场 - 一卷到底
到了下半年,主要是转到内部落地的项目,这次更方面条件合适,机会难得,不搞则以,搞就必须搞成
对我而言,打野快两年了,也该搞点事情了,内部沟通的时候,我也是表了决心的。如果放在战场,那就立下军令状的了,哈哈~
于是,下半场就开始卷起来了,嗯,卷飞了的那种,在广州办公区,我已经算是卷的那一批了(不过,算不上卷王,总还有人比你更卷,哈哈)
好在卷归卷,落地目标也算达成了,我觉得也是一次不错的体验,也有比较多的感悟,挑两个感触比较深的说说~
拿结果
推内部项目是目的性很强的,一切为了拿结果
哈哈,下半年最大的变化估计就是摇人了,在大公司里干活,遇到问题能摇对人,摇得动人,已经是生存的核心竞争力了~
当然还有,各种拉通对齐也是少不了的,每个人都有自己的目标结果,甚至还有一些屁股问题,要推动别人干活,也是不容易的~
规模化作战
当然,以上并没有揶揄的意思,大公司的协作机制就是不一样的
经过下半年一番折腾,也算是比较有深度的体验了,这种人挨人的规模化作战方式
以我浅薄的理解,大公司的好处就是人多,可以规模化作战,此时人与人之间的协作距离就很近了,这种就免不了一定的摩擦
拍脑袋的数据,如果 5 个人的团队,能发挥 4 个人的战力值,也就是人效比 0.8,应该也是不错的了
相对而言,创业公司就比如特种兵,每个人的空间通常都比较大,但是呢,打法肯定是不一样的了
AI
以 ChatGPT 为代表的 AI,确实一直都在持续给我们带来震撼
今年我也一直有在关注了解 AI,不过一直也没有躬身入局进去玩一玩
对我最大的变化就是,搜索引擎用得少了,公司内网的 GPT 反倒是首选的了(感谢公司提供的 GPT,最近还给升级到了 GPT 4.0 Turbo)
之前也写过一篇文章,我内心是愿意相信 AGI 的,但是嘛,眼下而言,我觉得:
- AI 好玩的应该是创新应用,基于大模型的能力,给我们的生活带来更美好的体验
- 我还是先搞好网关这个老本行吧,把网关搞好,来支撑 AI 创新应用,也算是为 AI 添砖加瓦了
出去走走
今年疫情算是彻底放开了,一家人也算是顺顺利利过来了
虽然上周家里娃赶上甲流,居家呆了差不多一周,不过,小孩好得也挺快的,倒是我感觉快被传染了,还好即时蹭了小孩的药吃了,哈哈~
今年安排了两次家庭出游,一次北京,终于带家里老人坐了飞机,去了北京兜了一圈,也算是完成了老人家的心愿
对我而言,去哪里玩倒不是那么重要,主要是能陪着他们走一走,对我这种常年在外的,这种专程陪伴也是难得
还有十一去了趟潮汕,算是休闲游,扔掉工作,丢带烦恼,享受岁月静好,哈哈~
希望明年也可以继续走起~
最后
啰啰嗦嗦写得有点多了,时间也不早了,就这么多吧,哈哈~
今年整体感觉还是不错的,虽然也有一些遗憾,不过该做的基本都做到了
明年,希望工作上,整体节奏把握得更好一些,更从容一些,不用卷得那么辛苦,也可以顺畅推进
当然,今年下半年开源搞得相对少了些,明年还是要继续玩起的。这不,这周六就要去 Gopher Meetup 深圳站吹水了,哈哈,欢迎面基约起~
生活上嘛,希望顺顺利利的吧,最好能降低点体重,哈哈~
发现年终总结还是工作居多,或许这就是打工人吧,哈哈~