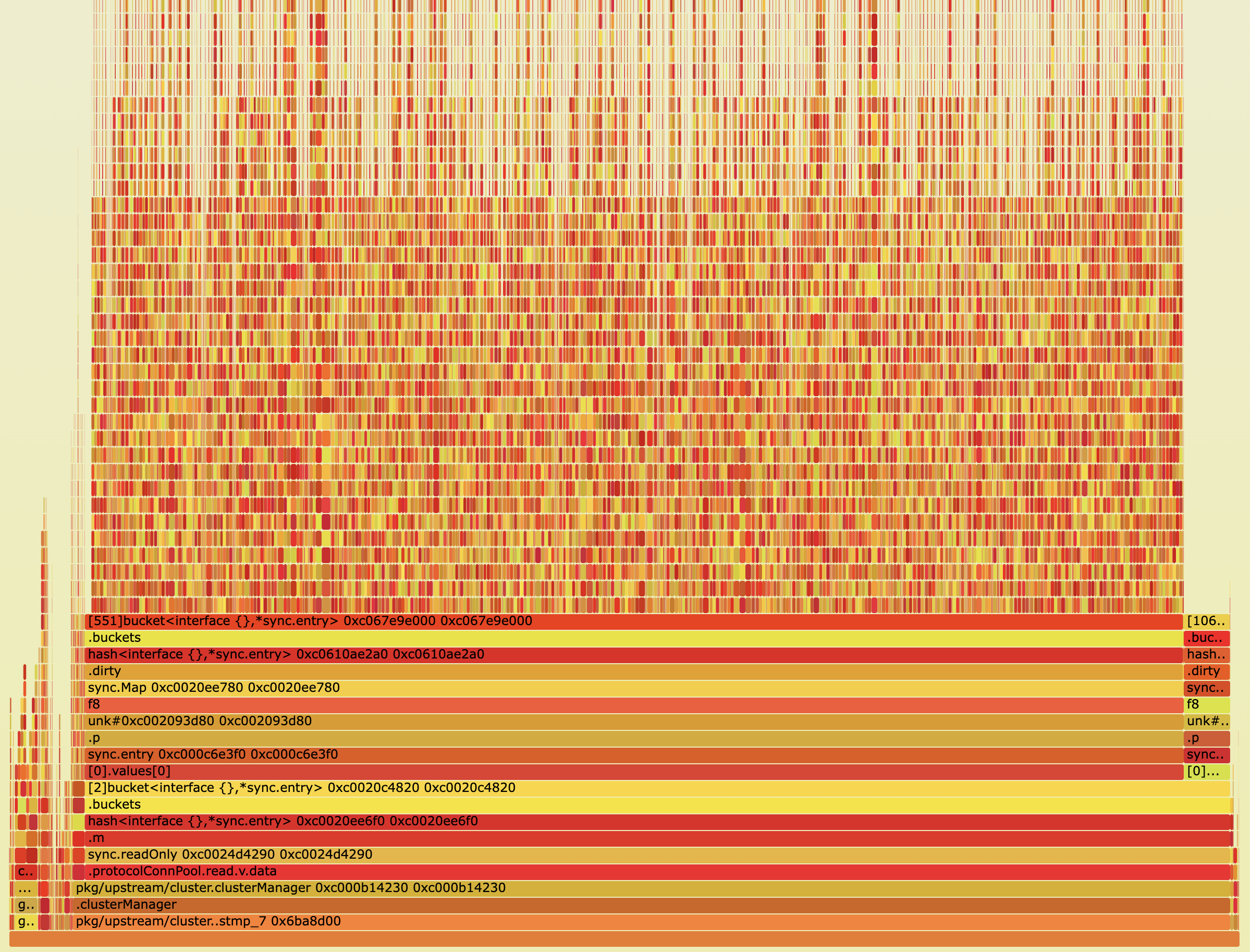
书接上回,从一个 core 文件,生成内存引用关系火焰图时,虽然可以从 core 文件中,读到所有的内存对象,但是并不知道它们的类型信息。
这是因为 go 作为静态类型语言,在运行时,内存对象的类型是已知的;也就是说,并不需要想动态类型语言那样,为每个内存对象,在内存中存储其类型信息(Go 有点例外的是 interface)。
比如这个 go 语言例子:
1
2
3
4
5
6
7
8
| type Foo struct {
a uint64
b int64
}
func foo(f *Foo) int64 {
return f.b
}
|
foo 函数在使用 f 这个指针时,并不需要判断其类型,直接读一个带偏移量地址就能得到 f.b,也就是一条指令:mov rax, qword ptr [rax + 8],就是这么简单直接。
再看 Lua 语言这个例子
1
2
3
4
| function foo(f)
return f.b
end
foo({ b = 1 })
|
foo 函数在执行的时候,首先得判断 f 的类型,如果是 table,则按照 key 取 b 的值;如果不是,则抛运行时 error。
能够运行时判断 f 的类型,是因为 Lua 中变量是用 TValue 来表示的,这个 TValue 结构中,就有一个头信息用来存储变量类型。
逆向类型推导
逆向类型推导的逻辑是,根据已知内存的类型信息,推导被引用的内存对象的类型信息。
比如这个例子:
1
2
3
4
5
6
7
8
| type Foo struct {
a uint64
b int64
}
type Bar struct {
f *Foo
}
var b Bar
|
如果我们知道了 b 的类型是 Bar,那么 b 中第一个 field 指向的内存对象,就是 Foo 类型了(前提是合法的内存对象地址)
既然存在推导,那我们怎么知道一些初始值呢,一共有两类来源:
- 全局变量
- 协程中每一帧函数的局部变量
全局变量
go 在编译的时候,默认会生成一些调试信息,按照 dwarf 标准格式,放在 ELF 文件中 .debug_* 这样的段里。
这些调试信息中,我们关注两类关键信息:
- 类型信息,包括了源码中定义的类型,比如某个 struct 的名字,大小,以及各个 field 类型信息
- 全局变量,包括变量名,地址,类型
调试信息中的,全局变量的地址,以及其类型信息,也就是构成推导的初始值。
函数局部变量,要复杂一些,不过基本原理是类似的,这里就不细说了~
推导过程
推导过程,跟 GC mark 的过程类似,甚至初始值也跟 GC root 一样。
所以,全部推导完毕之后,GC mark 认为是 alive的内存对象,其类型信息都会被推导出来。
interface
Go 语言中 interface 比较类似动态类型,如下是空接口的内存结构,每个对象都存储了其类型信息:
1
2
3
4
| type eface struct {
_type *_type
data unsafe.Pointer
}
|
按照类型推导,我们能知道一个对象是 interface{},但是其中 data 指向对象,是什么类型,我们则需要读取 _type 中的信息了。
_type 中有两个信息,对我们比较有用:
- 名字
不过比较坑的是,只存了 pkg.Name 并没有存完整的 include path
这个也合理的,毕竟 go 运行时并不需要那么精确,也就是异常时,输出错误信息中用一下。不过在类型推导的时候,就容易踩坑了。
- 指针信息
具体存储形式有点绕,不过也就是表示这个对象中,有哪些偏移量是指针
有了这两个信息之后,就可以从全量的类型中,筛选出符合上面两个信息的类型。
通常情况下,会选出一个正确的答案,不过有时候选出多个,仅仅根据这两个信息还不能区分出来,一旦一步错了,后面可能就全推导不出来了。
我们给 go 官方 debug 贡献了一个补丁,可以进一步的筛选,有兴趣的可以看 CL 419176
unsafe.pointer
其实,在上面的 interface 示例中,最根源的原因,也就是 data unsafe.pointer,这个指针并没有类型信息,只是 interface 的实现中,有另外的字段来存储类型信息。
不过,在 go runtime 中还有其他的 unsafe.pointer,就没有那么幸运了。
比如 map 和 sync.map 的实现都有 unsafe.Pointer,这种就没有办法像 interface 那样统一来处理了,只能 case by case,根据 map/sync.map 的结构特征来逆向写死了…
我们给 go 官方 debug 贡献了 sync.map 的逆向实现,有兴趣的可以看 CL 419177
隐藏类型
除了源码中显示定义的类型,还有一些隐藏的类型,比如,Method Value,Clouse 的实现中,也都是用 struct 来表示的,这些属于不太容易被关注到的 “隐藏”类型。
Method Value 在逆向推导中,还是比较容易踩坑的,我们给 go 官方 debug 贡献了这块的实现,有兴趣的可以看 CL 419179
相比 Method Value 这种固定结构的,Closure 这种会更难搞一些,不过幸运的是,我们目前的使用过程中,还没有踩坑的经历。
还有吗
这种逆向推导要做到 100% 完备,还是挺难的,根本原因,还是 unsafe.pointer。
reflect.Value 中也有 unsafe.pointer,据我所知,这个是还没有逆向推导实现的,类似的应该也还有其他未知的。
甚至,如果是标准库中的类型,我们还是可以一个个按需加上,如果是上层应用代码用到的 unsafe.pointer,那就很难搞了。
还有一种可能,推导不出来的原因,就是内存泄漏的来源,我们就碰到这样一个例子,以后有机会再分享~
也还好
幸运的是,如果是只是少量的对象没有推导出来,对于全局内存泄漏分析这种场景,通常影响其实也不大。
另外,对于一个对象,只需要有一个路径可以推导出来,也就够了。
也就是说,如果一条推导线索因为 unsafe.pointer 断了,如果另外有一个线索可以推导到这个对象,那也是不影响的。因为从 GC root 到一个 GC obj 的引用关系链,可能会不止一条。
最后
Go 虽然是静态类型语言,不过由于提供了 unsafe.pointer,给逆向类型推导带来了很大的麻烦。好在 Go 对于 unsafe.pointer 的使用还是比较克制,把标准库中常用到的 unsafe.pointer 搞定了,基本也够用了。
理论上来说,逆向推导这一套也适用于 C 语言,只不过 C 语言这种指针漫天飞的,动不动就来个强制类型转换,就很难搞了。