大模型太吃资源了,各种计算、memory、带宽 bound,导致引擎并发能力很弱,对负载均衡依赖很高
往后看,AIGW 要做的,不仅是要均衡,而是要承担时延 SLO
确实好久没写了,这一年都在 “卷” AI 网关,内部落地,业界演进,节奏都非常快,忙也是现实
今儿开个头,开启一个新阶段,后面保持节奏继续走起
负载均衡
今儿从负载均衡开始聊起,在通算时代,对于网关来说,这是经典的基础能力
Round-robin,权重轮询,最小连接数,一致性哈希,也可谓是脍炙人口
但是,在智算时代,负载均衡是 AI 网关的核心价值,已经逐步在成为行业共识了
为什么呢,小小负载均衡,有这么重要(难搞)么?
推理的计算特征
这要从大模型推理的计算特征说起了
(大模型推理的计算过程,要讲清楚了,也不容易,咱们这里只聊跟负载均衡有关系的)
计算量大
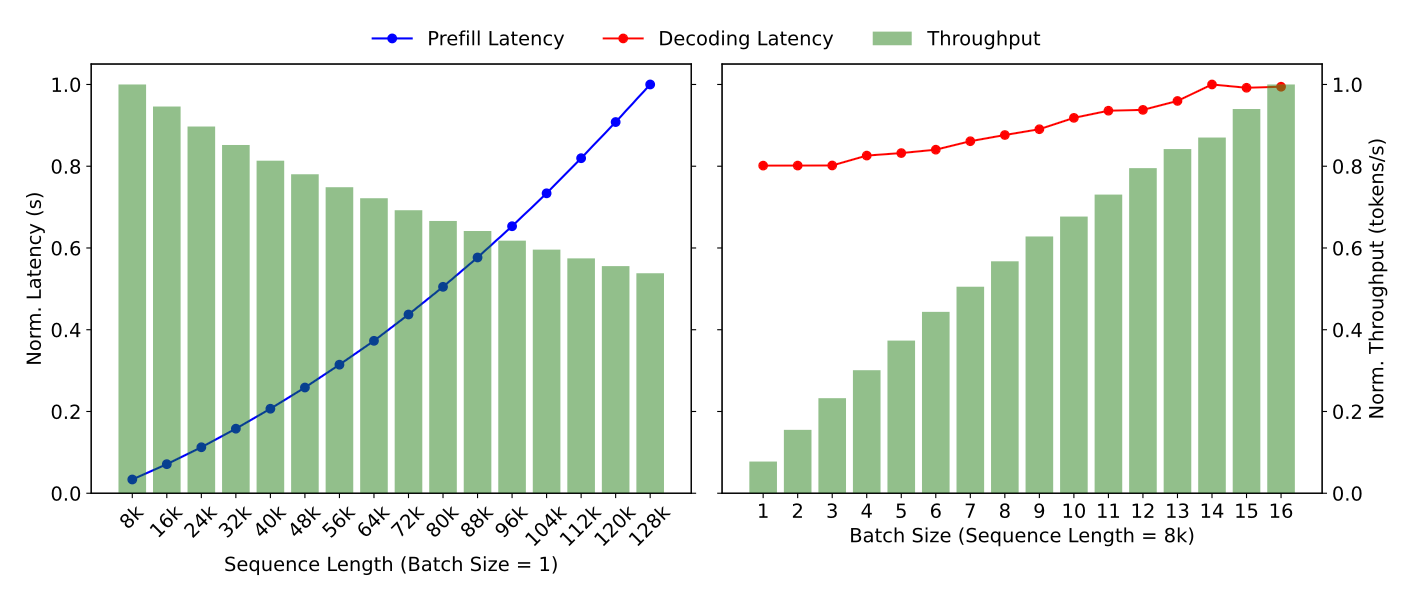
大模型推理请求的计算量都很大,相比通算的业务请求,多了好几个数量级
以 deepseek v3 为例,一个 4k token 输入的请求,纯 prefill 阶段,就需要 8 卡的 H20 计算几百毫秒
单点并发小
对于通算应用,单点几千几万的并发也很常见
而在推理场景下,单点的并发能力就弱很多了,prefill 阶段可以认为没并发(开启 dp 也算有点),decode 阶段一般也就是几十上百
波动很大
推理请求的计算量,随着输入输出长度变化,差异也非常大,不同请求的计算量,相差个几十上百倍,也很常见
尤其是输出长度,由于自回归特性,都不好提前感知
prefix 语义 KVCache
大模型的计算结果也可以缓存(KVCache),对于提升性能也很重要,但是,缓存复用需要遵守 prefix 语义
通算场景下的缓存,通常是基于某个 key 来做哈希的规则,相对来而,推理这个要复杂多了
难在哪
简单说,在推理场景,因为推理引擎抗并发小(各种 计算、memory bound),更需要负载均衡,但是,也更难做好负载均衡
那么,难在哪里呢
在通算场景下,服务的负载通常和请求数,或者并发数正相关,只需要做到请求/并发数均衡基本就够了
但是,由于上述推理的计算特征,推理服务的负载,跟请求数并不是正相关
于是,有了这三个关键的具体问题:
- 哪些指标可以反映负载
- 如何获取到,时效性如何
- 什么样的负载算法来决策
具体怎么解,就留到下篇了
最后
关于推理的计算特征,看 Mooncake 论文里的这个图,可以有一些直观的体感