看起来有点标题党的嫌疑,用了「下半场」这么个烂大街的词。
但是,从我个人的经历来看,又是一个非常贴切的描述。
个人经历
那么,就先说说我的个人经历
Nginx 老炮
我以前是搞 OpenResty/Nginx 的,玩了十来年,算是个老炮玩家。
最早接触 Nginx,是 2010 在淘宝实习,很荣幸就在春哥所在的量子统计团队。
不过,工作上跟春哥直接接触不多,好在,那会春哥很喜欢搞分享,听过春哥很多分享,也知道春哥在搞 ngx_lua module。
此后十年,算是亲历了 Nginx 的崛起,从给 PHP 当 webserver,到统一的网关接入,从 CDN 到数据中心,Nginx 已经是网关的主流方案。
而我个人,也在春哥的 OpenResty 社区,一路打怪升级,从开源迷弟,走到老司机,有幸成为了 OpenResty 的核心开发者。
哈哈,春哥是我的贵人,对我帮助非常大,这里暂且不表,以后有机会再单独
Envoy extension maintainer
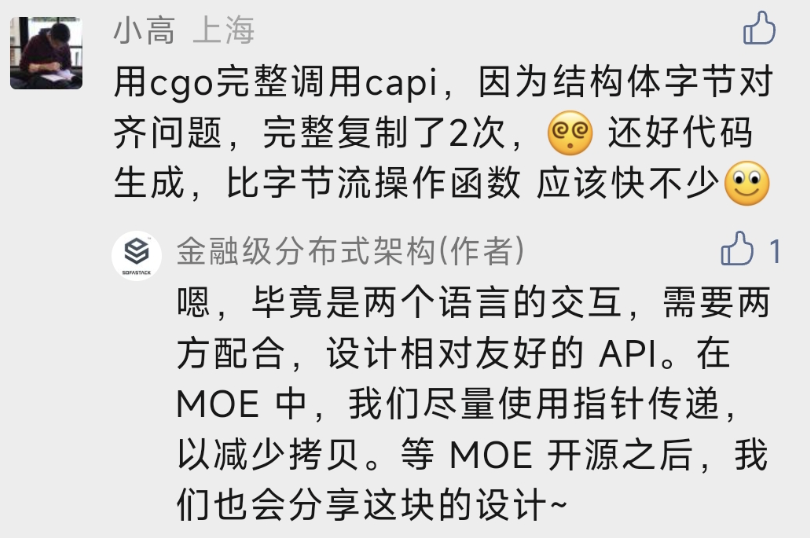
差不多两年前,加入了蚂蚁的 MOSN 团队,主要搞 MoE 架构,也就是 MOSN on Envoy。
在 Envoy 里面,我们主要是搞 Golang filter 扩展,将 Golang 嵌入 Envoy,支持用 Golang 来写 Envoy 扩展。
在大家的通力协作下,我们也混了个 Envoy 的 extension maintainer。
最近几年,随着微服务的发展,Service Mesh 的兴起,内网的东西向流量,也开始被网关代理管理起来了。
作为后起之秀的 Envoy,也借势成为了东西向网络代理的首选。
下半场
为什么说是下半场了呢
现状
经过多年的赛跑,Envoy 在东西向已经站住了脚跟,在南北向虽然也有建树,但是王者还是 Nginx。
从我个人的体感来看,Envoy 和 Nginx 现在就是一个对象相持阶段。
像接入层这种关键性的基础设施,稳定是第一重要的因素,而从 Nginx 的各种宣发文章中,以及老用户的顾虑中,也可以看到这是 Nginx 的主要卖点之一。
这注定是一场攻坚战,要想决胜也不是一朝一夕之功。
所以,我觉得是下半场了,已经不是跑马圈地的阶段了,而是攻坚战了。
k8s Gateway API
作为下半场,我觉得有两个看点,其一就是,k8s Gateway API。
在 k8s 体系中,承担南北接入流量的是 Ingress,而 Ingress 的数据面实现,主流还是 NGINX Ingress Controller。
Ingress 确实由于早期设计的不合理,给了大家掀桌子,重新洗牌的机会。
在去年,我们内部有过一次关于 k8s Gateway API 的严肃讨论,那时我们注意到 k8s Gateway API 的玩家已经聚集了主要的网关玩家,包括 Nginx 和 Envoy 两大阵营,以及其他多路玩家。
让这些人排排坐起,把事情推进下去,k8s Gateway API 能做成也是必然的事。
而能让这些人排排坐起的主要动因,就是大家对重新洗牌的共同诉求。大家感兴趣的话,可以看看出力多的几家,那就是掀桌子的主力,哈哈。
对于 Envoy 而言,这也是进一步抢夺网关市场的机会,这将是重头戏。
东西南北融合
按照现在的主流选择,东西向用 sidecar,南北向用集中式网关。
而 sidecar 这种部署形态,并不太适合网络作为基础设置的定位。又催生出了 istio ambient mesh 这种架构,其中 waypoint 这个组件,也是以 Deployment 的形式部署了。
在蚂蚁,我们也早在 ambient mesh 之前,就在推动 NodeSentry 这种 Node 化的部署架构,说明大家面临的问题是一样的,sidecarless 也是人心所向。
除了数据面的部署形态的部分趋同,还有控制面的资源定义,k8s Gateway API 原本是为了南北向设计的,但是,以 linkerd 为代表的 Mesh 用户,希望 k8s Gateway API 也可以兼容 Mesh 场景,于是就有了 GAMMA,Gateway API for Mesh Management and Administration。这也将某种程度的,驱动东西南北的融合。
随着技术实现上的融合,使得业务上的融合也变得可能,我相信后续业务上的融合点,也会变得多起来。
做点什么
作为网关领域的从业者,我们注定要躬身入局的,那我们选择做点什么呢?
虽然,在云原生这一波浪潮中,网络作为基础设施,也是被标准化,资源化的重点。数据面的实现,并不是业务关心的第一要素。
但是,从技术的角度看,网关是从数据面为基础向上发展的,所以,我们第一阶段重心投入在数据面。
也就是我们今年在推动 Envoy Golang 扩展,这将很大程度的提升 Envoy 的可扩展能力,这是未来 Envoy 能否成为王者的重要因素。
因为,当资源标准化之后,对于标准的能力,大家都是标配了,能否具备高效的扩展方式,来解决长尾的定制扩展需求,将是未来网关选型的重要因素之一。
在 Envoy 数据面上立住脚之后,我们也在向上发展,投入控制面,做产品。
相信不久之后,大家就可以看到我们在控制面,产品层的产出了
未来
Nginx 和 Envoy 也只是目前网关市场的两个头部玩家,至少在开源圈子里是这样的。
以后会不会有冒出个新的头部玩家,也未可知。不过网关这种基础设施的变更周期也没那么快,没有足够的驱动因素,也很难达成掀桌子的共识。
不管后续又来了哪个玩家,上面这些发展趋势,我估计是很难撼动的了,游戏规则已经基本清晰,接下来就看刺刀怎么拼了。
至于未来谁是云原生时代的王者,作为一个用脚投票了的从业人员,我觉得依然有必要,保持开放的心态。
最终的王者,没准会是 AI,哈哈